Fx-Normalization#
Introduction#
Automatic music mixing using deep learning has shown promise, but previous methods have not yet achieved the level of professional audio engineers. While it’s been hypothesized that a large enough dataset could resolve this performance bottleneck, collecting dry (unprocessed) audio data is challenging, as it is unusual for musicians and record labels to provide multitrack dry recordings. Thus, it is believed that this limitation has affected the performance of existing models.
Research Question#
Can we use wet (processed) multitrack music data to train deep learning models for automatic music mixing ?
The Fx-Normalization Method#
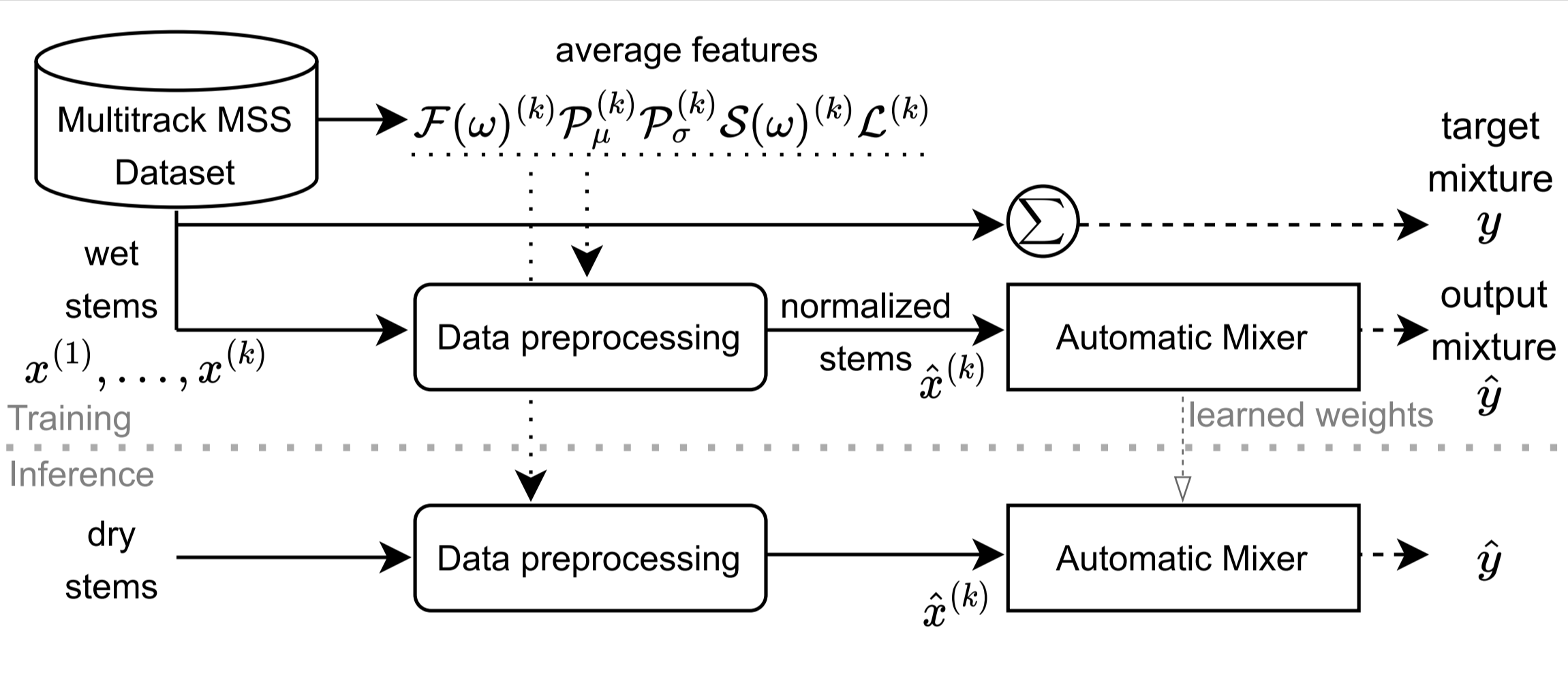
Fig. 24 Fx-Normalization for automatic music mixing#
The paper “Automatic music mixing with deep learning and out-of-domain data” [MartinezRamirezLF+22] introduces Fx-Normalization, a novel data preprocessing method that allows the use of out-of-domain data (wet multitrack recordings) to train supervised deep learning models for automatic mixing.
The method can be summarized as follows:
Data preprocessing: The system analyzes a dataset of wet multitrack recordings, computing average statistics/features related to various audio effects.
Fx-Normalization: Based on these features, the system “effect-normalizes” the wet stems, thus enabling the supervised training of a deep neural network. Normalization schemes for loudness, EQ, panning, dynamic range compression (DRC), and reverberation are applied.
Training: Models learn to undo or denormalize the input Fx-Normalized stems, thus approximating the original mix.
Inference: The same preprocessing is applied to dry data, yielding a fully automatic mixing system.
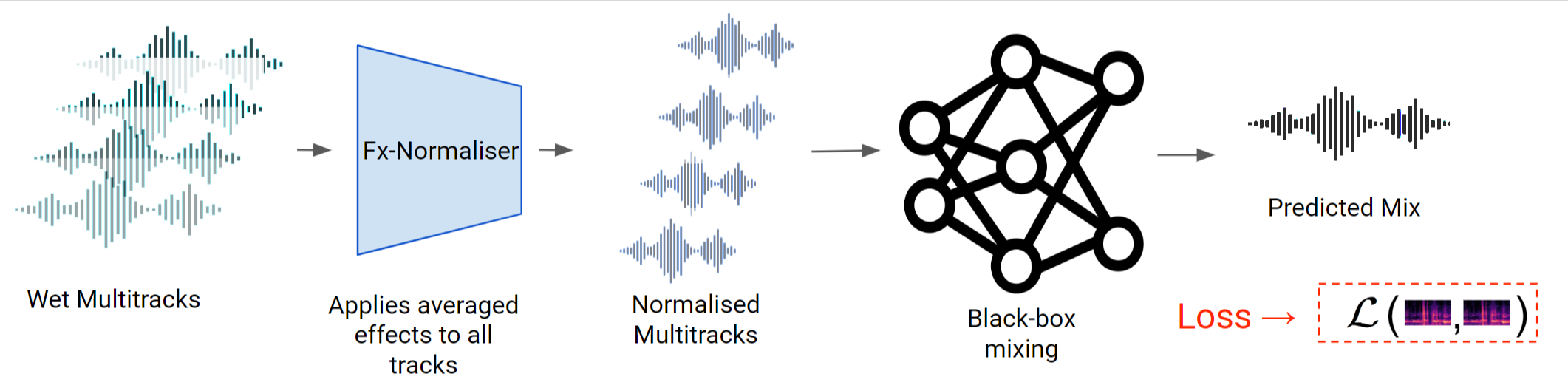
Fx-Normalization Process#
Loudness: Compute average loudness (LUFS) and normalize each stem.
Equalization: Compute average frequency magnitude spectrum and perform EQ matching.
Panning: Calculate average spectral-panning position and re-pan each frequency bin accordingly.
Dynamic Range Compression: Compute average onset peak level and standard deviation, then based on these values, apply further compression to upper-bound the peak levels of the stems.
Reverberation: Use data augmentation to add reverberation stochastically. Thus, the process of learning to “get reverberation right” is carried out by the network as it learns to filter out the additional reverberation.
CRAFx2 - Architecture#

Fig. 25 Block diagram of CRAFx2#
The paper proposes a new architecture, henceforth referred to as CRAFx2, which combines models from audio effects modeling and source separation. Specifically, it integrates the convolutional and recurrent audio effects modeling architecture (CRAFx) from [MartinezRamirezBR20] and Conv-TasNet [LM19]. It consists of:
Adaptive Front-end: Learns a filter-bank and frequency decomposition.
Latent-space Mixer: Uses stacked TCNs and BLSTMs to learn a mixing mask.
Mixing Back-End: Applies the mask, performs dynamic equalization and reverberation filtering, and uses a Squeeze-and-Excitation Block for loudness and panning.
Loss Function#
The paper explores variations of a stereo-invariant loss function, incorporating perceptual aspects through A-weighting pre-emphasis and low-pass FIR filters.
Datasets#
The study uses both small (MUSDB18) and large (PrivateDataSet + MUSDB18) datasets of wet stems for training and validation. A private set of 18 dry multitrack songs is used for testing.
Listening Test#
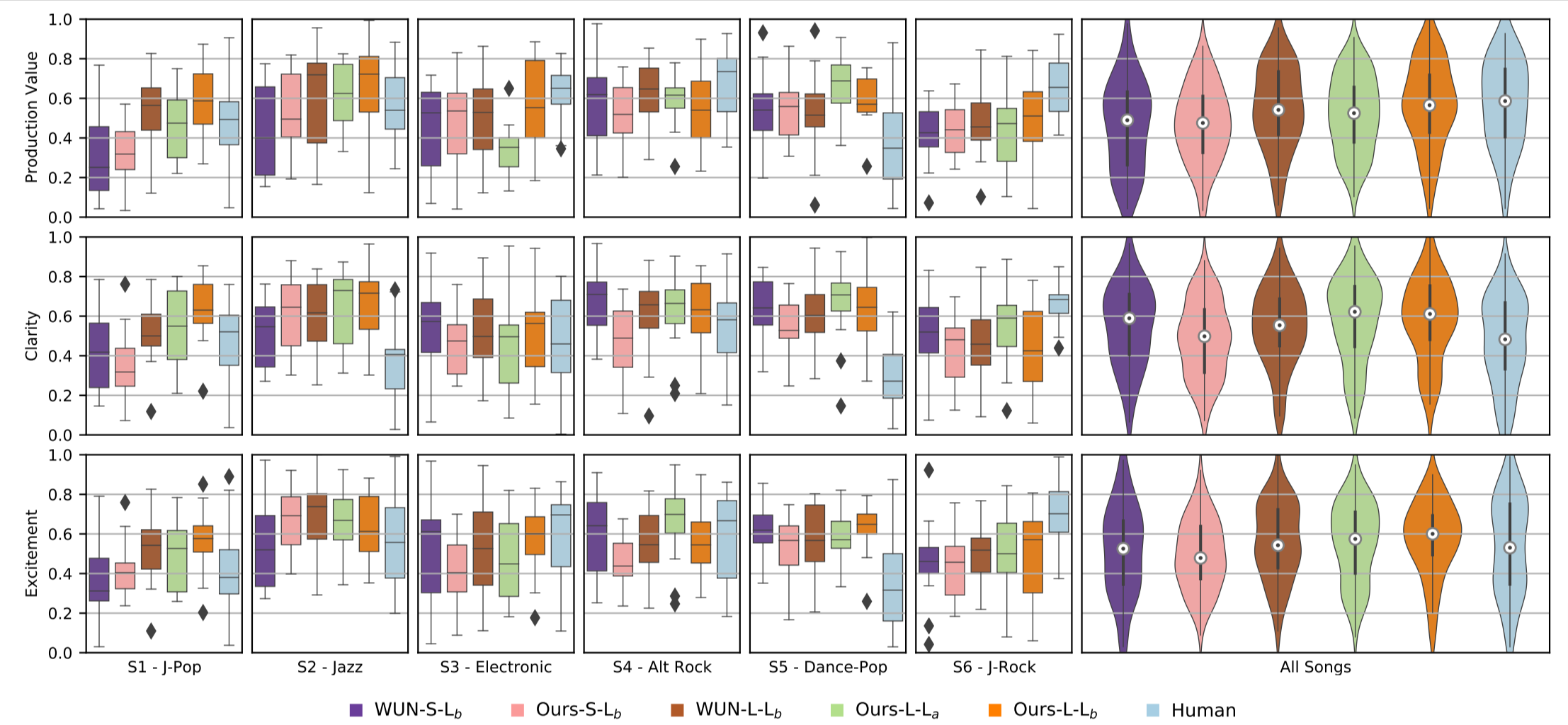
Fig. 26 Listening test boxplots and violin plots for all individual six songs (S1 to S6) and all songs, respectively.#
A listening test was designed for professional mixing engineers, evaluating mixes based on Production Value, Clarity, and Excitement. The test included the 4 dry stems as references. This approach allowed the ratings to reflect the quality of transformation on each stem as applied by the mixing systems. Fourteen participants with an average mixing engineering experience of 11.6 years took part in the test. In total, there were six different songs, and for each song, six different mixes were presented.
Results showed that the Fx-Normalization approach produced mixes that scored higher in Clarity and were indistinguishable from professional mixes in terms of Production Value and Excitement.
Conclusion#
Fx-Normalization successfully leverages wet data to train deep learning networks for automatic music mixing. The method performs automatic loudness, EQ, panning, compression, and reverberation mixing, producing results comparable to professional human-made mixes.