Differentable Mixing Style transfer#
In contrast to MST, Diff-MST is a parameter estimation approach to mixing style transfer that explicitly defines the structure of a mixing console using differentiable effects and utilizes a transformer-based neural network architecture to predict the mixing console parameters based on the analysis of the input tracks and reference song [VSR+24].
The system employs two encoders, one to capture a representation of the input tracks and another to capture elements of the mixing style from the reference. A transformer-based controller network analyses representations from both encoders to predict the differentiable mixing console (DMC) parameters. The DMC generates a mix for the input tracks using the predicted parameters in the style of the given reference song. Given that the system oversees the operations of the DMC rather than directly predicting the mixed audio, this system circumvent potential artefacts that may arise from neural audio generation techniques. This also creates an opportunity for further fine-tuning and control by the user.
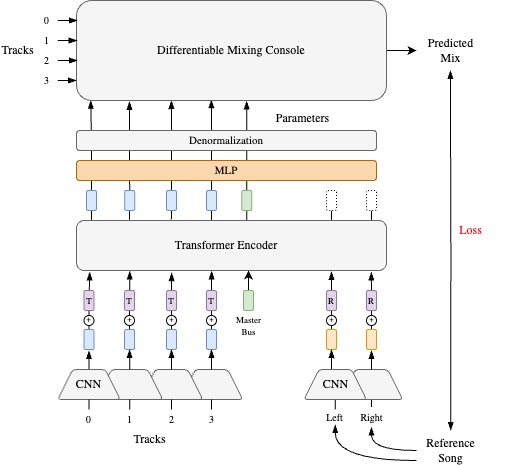
Fig. 27 Diff-MST Architecture#
Encoder#
The encoder consists of a convolutional network based on the magnitude spectrum. It computes spectrograms by employing a short-time Fourier transform with a Hann window of size \(N\) = 2048 and a hop size of \(H\) = 512. The generated magnitude spectrogram is then processed through the convolutional layers. The resultant convolutional encodings are subsequently fed into a linear layer, producing a final embedding of size 512. The model includes separate shared-weight encoders: \(f_{\theta r}\) for the reference mix and \(f_{\theta t}\) for the input tracks. Each channel of stereo audio is treated as an individual track. Consequently, the stereo mix and any other stereo input tracks are loaded as separate tracks. Embeddings are computed by passing \(T\) and \(M_r\) through the encoder.
Transformer-based Controller Network#
The controller features a transformer encoder and a shared-weight MLP. The transformer encoder generates style-aware embeddings using self-attention across the output of the spectrogram encoder \(f_{\theta r}\) and \(f_{\theta t}\) and a master bus embedding which is learned during training. The MLP predicts the control parameters corresponding to the channel strip for each track, and the master bus embeddings are used to predict the master bus control parameters. A shared weight MLP is used to predict channel strip parameters for each channel. We generate the predicted mix \(M_p\) by passing the control parameters through the DMC along with the tracks. This architecture enables our system to be invariant to the number of input tracks
Differentiable Mixing Console#
Multitrack mixing involves applying a series of audio effects, termed a channel strip, to each channel of a mixing console. These effects are utilized by audio engineers to address various issues such as masking, source balance, and noise. In our approach, we propose a differentiable mixing console (DMC) that integrates prior knowledge of signal processing. The DMC applies a sequence of audio effects including gain, parametric equalizer (EQ), dynamic range compressor (DRC), and panning to individual tracks, resulting in wet tracks. These wet tracks are then combined on a master bus where stereo EQ and DRC are applied to produce a mastered mix. Incorporating a master bus in the console facilitates workflow optimization, as mastered songs commonly serve as references. To enable gradient descent and training within a deep learning framework, the mixing console must be differentiable. We achieve this by utilizing differentiable effects from the dasp-pytorch library.
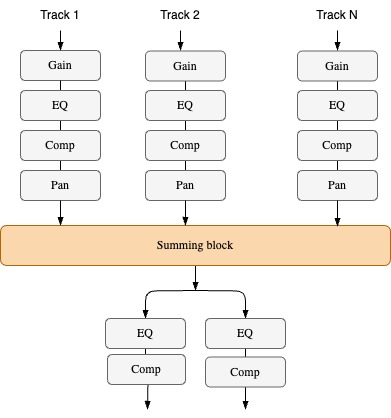
Fig. 28 Differentiable Mixing Console#
Audio Production Style Loss#
The style of a mix can be broadly captured using features that describe its dynamics, spatialization, and spectral attributes. Two different losses are proposed to train and optimize the models.
Audio Feature (AF) loss: This loss comprises traditional MIR audio feature transforms. These features include the root mean square (RMS) and crest factor (CF), stereo width (SW), stereo imbalance (SI), and barkspectrum (BS) corresponding to the dynamics, spatialization, and spectral attributes, respectively. The system is optimized by calculating the weighted average of the mean squared error on the audio features that minimizes the distance between predicted mix and the reference song. For more information, refer to the paper.
MRSTFT loss: The multi-resolution short-time Fourier transform loss [SR20] [EHGR21] is the sum of \(L_1\) distance between STFT of ground truth and estimated waveforms measured in both log and linear domains at multiple resolutions, with window sizes \(W \in [512, 2048,8192]\) and hop sizes \(H =W/2\). This is a full-reference metric meaning that the two input signals must contain the same content.
Training#
The models are trained end-to-end using two different methods.
Method 1#
The data generation technique used in [SBR22] is extended to a multi-track scenario. A \(t=10\) sec segment is randomly sampled from input tracks, and a random mix of these input tracks is generated using random DMC parameters. The segment of the randomly mixed audio and the input tracks is split into two halves: \(M_{rA}\) and \(M_{rB}\) and \(T_A\) and \(T_B\) of \(t/2\) secs each, respectively. The model is input with \(T_B\) as input tracks and \(M_{rA}\) as the reference song. The predicted mix \(M_p\) is compared against \(M_{rB}\) as the ground truth for backpropagation and updating of weights. Using different sections of the same song for input tracks and reference song encourages the model to focus on the mixing style while being content-invariant. This method allows the use of MRSTFT loss for optimization as we have the ground truth available. The predicted mix is loudness normalized to -16.0,dBFS before computing the loss. We train models with 8 and 16 tracks using this method with MRSTFT loss and MRSTFT loss and AF loss fine tuning.
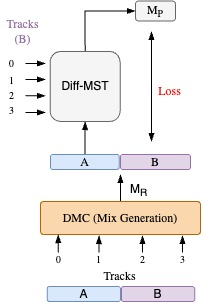
Fig. 29 Training strategy for Method 1#
Method 2#
A random number of input tracks between 4-16 for song A is sampled from a multitrack dataset, and a pre-mixed real-world mix of song B from a dataset consisting of full songs is used as the reference. The model is trained using AF loss computed between \(M_p\) and \(M_r\). This method also allows us to train the model without the availability of a ground truth. Unlike Method 1, this approach exposes the system to training examples more similar to real-world scenarios where the input tracks and the reference song come from a different song. However, due to the sampling, some input track and reference song combinations may not be realistic. We train a model with upto 16 tracks using this method using AF loss.